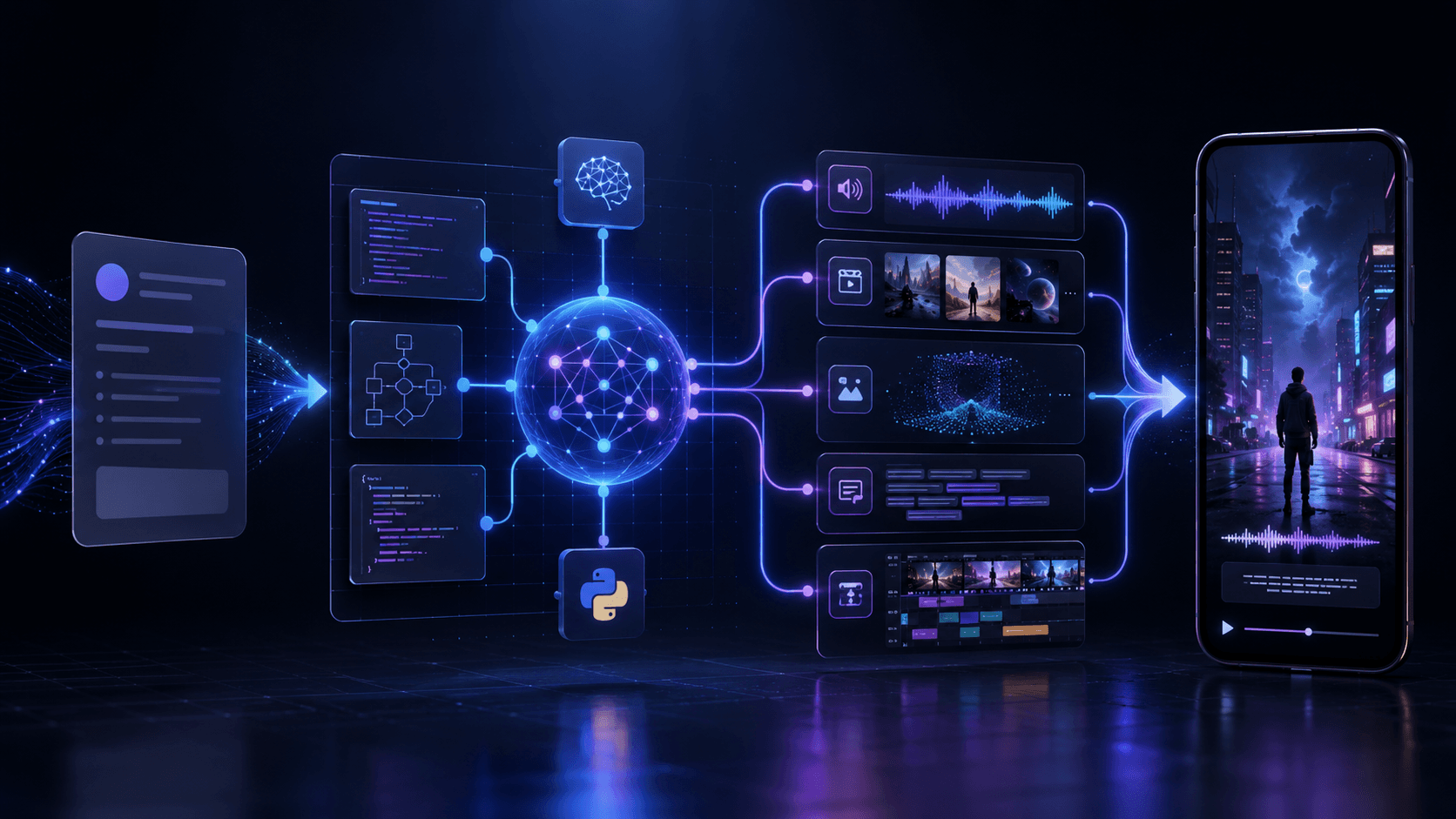
Aginx — мой контент-завод: CLI-инструмент, который из текстового брифа собирает готовый вертикальный ролик до 60 секунд. Один контур без ручных действий: бриф → сценарий → генерация видео, голоса и музыки → монтаж с субтитрами. На выходе mp4 для Reels / Shorts / TikTok.
Сразу цифры:
- ~5 минут от брифа до готового файла (без учёта итераций по сценарию);
- ~250 ₽ себестоимость 60-секундного ролика через API;
- ≈0 ₽ за видео в экспериментальном контуре — про него в конце.
Ролик ниже собран этим пайплайном целиком — сценарий, видеосцены, озвучка, музыка, субтитры, монтаж. Руками не тронуто ничего:
Сразу рамка, чтобы не было завышенных ожиданий: это не продакшен-система и не SaaS под SLA, а компактный инженерный эксперимент — CLI-контур на десятки прогонов, а не тысячи задач в проде. Собран он для проверки гипотезы: можно ли пройти путь от брифа до ролика, не утонув в хаосе LLM-ответов и внешних API. Интересен он тем, что продакшен-проблемы в нём настоящие: валидация нестабильного вывода модели, падения провайдеров, региональные блокировки, повторный запуск без пересоздания уже оплаченных артефактов.
Дальше — как это устроено, во что обходится и на какие грабли я наступил.
Архитектура: четыре стадии, один контур
Стек: Python, asyncio, Typer, Pydantic, httpx, ffmpeg. Никакого фреймворка для «AI-агентов» — обычный оркестрируемый пайплайн.
Ключевые роли:
- Orchestrator — единственное место, где живёт LLM. Получает бриф, возвращает структурированный сценарий: сцены с длительностями, промпты для визуала, текст озвучки, промпт для музыки, крючок первой фразы.
- Три пайплайна — аудио, визуал, сборка. Друг о друге не знают, общаются через файлы на диске.
- MediaProvider — маршрутизатор медиагенерации: сначала fal.ai, при ошибке — Replicate. Модели задаются конфигом: Flux для картинок, Kling v3 для видео, Stable Audio для музыки.
Пайплайн умеет три формата ролика, и это решение принимает сценарист (или бриф принудительно): broll — сгенерированные видеосцены, slideshow — картинки с движением камеры, talking_head — сгенерированный аватар, анимированный под озвучку через LivePortrait.
Structured output без магии
Самая переносимая часть проекта — то, как LLM встроена в контур. Никакого function calling и цепочек агентов: схема в промпте, json.loads, Pydantic.
Сценарий описан обычными Pydantic-моделями с ограничениями:
class Scene(BaseModel):
index: int
duration: float = Field(ge=1.0, le=30.0)
visual_prompt: str # английский, cinematic
narration: str # текст озвучки
mood: str
camera: str = "static"
class Script(BaseModel):
title: str
content_type: ContentType # broll | talking_head | slideshow
total_duration: float
scenes: list[Scene]
music_prompt: str
voice_id: str
voice_style: str
hook: str # первая фраза-крючокМодель получает схему прямо в промпте и инструкцию «Return ONLY valid JSON». А дальше главный принцип, на котором держится весь контур:
Модель предлагает — код решает. После парсинга ответа код перезаписывает всё, чему модели доверять нельзя:
content_typeиз брифа затирает выбор модели: если заказчик сказал «broll», сценарист не имеет права решить иначе;voice_idиз конфига авторитетнее того, что придумала модель;total_durationпересчитывается кодом как сумма длительностей сцен — арифметике LLM я не доверяю принципиально.
data = json.loads(raw)
# Бриф авторитетнее модели
if brief.content_type is not None:
data["content_type"] = brief.content_type.value
scenes = [Scene(**s) for s in data["scenes"]]
# Модели нельзя доверять даже сложение
data["total_duration"] = round(sum(s.duration for s in scenes), 1)
return Script(**data)Если Pydantic не принял ответ — генерация падает сразу, на этапе сценария, когда ещё не потрачено ни рубля на медиа. Это дешёвое место для ошибки, и пайплайн построен так, чтобы ошибки случались именно здесь.
Отдельная деталь: оркестратор дёргает Claude не через SDK, а субпроцессом через CLI — claude -p "<промпт>" --model claude-sonnet-4-6. Это был самый короткий путь до работающего сценариста. Расплата: таймаут 120 секунд, нет стриминга, процесс на каждый вызов. Для одного вызова на ролик — приемлемо; для сервиса с очередью я бы перешёл на API со structured output.
Экономика: из чего складываются 250 ₽
Себестоимость 60-секундного broll-ролика через API — около 250 ₽. Раскладка отрезвляет:
| Компонент | Сервис | Доля стоимости |
|---|---|---|
| Видеосцены | Kling v3 через fal.ai | почти 100% |
| Озвучка | Yandex SpeechKit | ~1 ₽ за минуту |
| Сценарий | Claude | копейки |
| Музыка | Stable Audio | копейки |
Из этой таблицы следуют все архитектурные решения про деньги:
1. Оптимизировать стоимость = оптимизировать видео. Всё остальное можно не считать. Отсюда режим slideshow: картинки Flux вместо видеосцен Kling — на порядки дешевле, для части задач (цитаты, анонсы, списки) качества достаточно.
2. Порядок стадий выбран по деньгам. Аудио генерируется первым: если TTS упал, платная видеогенерация даже не стартует. В коде это отдельный комментарий: «If TTS fails, do not start paid video generation».
3. Идемпотентность — это тоже про деньги. Каждый артефакт — сценарий, каждая сцена, голос, музыка — сразу пишется на диск. Пайплайн из пяти внешних API обязательно упадёт, вопрос когда. Команда resume продолжает задачу с места падения и пропускает готовые файлы: упавший на девятой сцене прогон не пересоздаёт восемь уже оплаченных.
if out.exists() and out.stat().st_size > 1000:
progress_cb(f"Сцена {scene.index + 1} уже есть, пропускаю...")
return outИ экспериментальная ветка: сейчас я гоняю видеогенерацию через бесплатный Hyperframe, управляемый агентами, — это отдельный от основного кода контур, и он сбивает стоимость видео к нулю. Пока это эксперимент, а не прод-решение: базовый путь через Kling остаётся эталоном по качеству. Но направление понятно — самая дорогая часть пайплайна дешевеет быстрее всех остальных.
Грабли
ElevenLabs забанил Россию
Лучший голос для русского была ElevenLabs. В какой-то момент сервис перестал работать из России — и это грабля, которую я так и не решил «красиво»: реэкспортные шлюзы добавляют хрупкости, которую я в контуре терпеть не хочу.
В коде осталась честная цепочка деградации: ElevenLabs (если ключ работает) → MiniMax speech-02 через fal.ai → Replicate. В рабочем контуре я в итоге оставил Yandex SpeechKit: рубль за минуту, никаких банов — но по живости голоса это хуже ElevenLabs. Это осознанный трейдофф: стабильность контура важнее последних процентов качества озвучки. Осадок остался.
Вывод шире, чем про TTS: в LLM-пайплайне каждый внешний провайдер — точка отказа. Сегодня rate-limit, завтра бан по региону. Поэтому абстракция провайдера с fallback-цепочкой нужна с первого дня — без неё контур встаёт при первой же смене правил на чужой стороне.
У каждой медиамодели свои рамки, и сценарист о них не знает
Kling принимает длительность строкой от «5» до «15» секунд. Сценарист может написать сцену на 3 секунды — модель всё равно сгенерирует 5. Pydantic-схема разрешает сцены от 1 до 30 секунд, а реальность провайдера — 5–15:
kling_duration = str(min(max(int(duration), 5), 15))Правильное решение — ограничения медиамоделей должны попадать в схему сценариста, а не клампиться молча на нижнем уровне. У меня пока второй вариант, и это техдолг.
«Return ONLY valid JSON» не работает
Сколько ни пиши в промпте «без markdown-фенсов, без пояснений», модель периодически возвращает ```json ... ```. Промптом это не лечится. Лечится тремя строками кода, которые срезают фенсы перед парсингом, — дешевле принять как данность.
Субтитры без таймстемпов
TTS отдаёт mp3 без пословных таймингов. Точную синхронизацию субтитров с речью из этого не получить. Компромисс: реальная длительность аудио берётся через ffprobe, текст распределяется по времени пропорционально длине текста сцен, дальше режется чанками по 7 слов. Не идеально — но стабильно и без дополнительных вызовов.
Вторая грабля там же: SRT + force_style в ffmpeg — боль с экранированием. ASS-формат стилизуется нативно, поэтому субтитры генерируются сразу в ASS и прожигаются одним фильтром.
Rate limit бесплатного тарифа
Replicate на бесплатном тарифе держит burst = 1. Между генерацией сцен стоит asyncio.sleep(2) — некрасиво, но это честная цена нулевого бюджета на резервного провайдера.
Чего здесь нет до настоящего продакшена
Чтобы слово «пайплайн» не звучало громче, чем есть: продакшен-системой я этот контур не называю. До прода ему не хватает как минимум:
- очереди задач и воркера вместо локального CLI;
- централизованных логов, метрик и алертов;
- лимита на стоимость одного прогона;
- retry/backoff-политик по типам ошибок;
- хранения артефактов вне локального диска;
- тестов на регрессии сценария, сборки и субтитров;
- approval-gate перед дорогой видеогенерацией.
Поэтому Aginx для меня — рабочий прототип: проверка архитектурных решений, которые потом переносятся в боевой контур.
Что в итоге
Контур работает: бриф уходит в CLI, через ~5 минут возвращается ролик с озвучкой, музыкой и субтитрами за ~250 ₽. Узкие места понятны: качество русского TTS после ухода ElevenLabs и цена видеогенерации — именно на неё направлен эксперимент с бесплатной генерацией через агентов.
Главный вывод: даже лёгкий LLM-эксперимент быстро перестаёт быть задачей про промпты. Как только появляются платные API, внешние провайдеры и риск потратить деньги на невалидный результат, начинаются обычные инженерные вопросы: где валидировать, что можно перезапускать, что нельзя пересоздавать и как контролировать стоимость ошибки. Если доводить такой контур до продакшена, главными станут те же решения — строгие схемы данных, fallback-провайдеры, идемпотентные стадии и порядок выполнения, выстроенный по цене ошибки.
Такой же контур собирается под другие задачи — например, генерацию отчётов из сырых данных или персонализированный контент под каждого клиента. Ищете инженера под LLM-пайплайны — резюме здесь. Есть задача под такой контур — пишите в Telegram.


